How Redbark Securely Syncs Your Financial Data
A technical look at how Redbark Sync moves your banking and brokerage transactions to destinations like Google Sheets — why transaction data never hits our database, and what minimal metadata we do hold to make the sync work.

How Redbark Securely Syncs Your Financial Data
Most financial sync tools store your transaction data in their own database as an intermediate step. Redbark doesn't. Your transactions, balances, and holdings flow directly from your bank to your chosen destination (Google Sheets or You Need a Budget) and our system retains none of the transaction payload. What we do hold is the minimum needed to make the sync work: the account metadata shown in the UI (institution name, account name, masked account number), your CDR consent records, and encrypted OAuth tokens. No transaction amounts, descriptions, merchants, or balances ever land in our database.
This post is a technical explanation of how the architecture works, what our database contains, and how you can verify the claims yourself. We'll cover:
- Why we built a pass-through architecture instead of a store-and-forward one
- What our database schema actually looks like (and what's absent from it)
- How a sync moves data from provider to destination without persisting it
- How credential encryption, CDR compliance, and webhook verification fit in
- What infrastructure and certifications we rely on
Every sync platform has to make a storage decision
When you connect a bank account to a sync service, the service has two architectural options. It can fetch your transactions, store them in its own database, and then push them to your destination on a schedule. Or it can fetch your transactions and write them directly to your destination, keeping nothing.
The first approach is simpler to build. Having a local copy of the data makes deduplication easy, enables features like search and filtering, and means the service can retry failed destination writes without re-fetching from the bank. Most platforms take this path.
We chose the second. Redbark is an orchestration layer. It stores the configuration for your syncs (which accounts, which destinations, which credentials) but never the financial data itself. The tradeoff is that we can't offer a transaction search UI or serve data from a local cache. Every sync requires a live call to the banking provider. But there is no database of customer financial data to breach, leak, or misuse.
What our database actually contains
A useful way to evaluate a data handling claim is to look at the schema. Here's ours:
The schema has six concerns: user accounts, connection metadata (which bank, what status), account metadata (account name, masked number, type, currency — enough to render the UI without re-fetching), sync configuration (which accounts map to which destinations), encrypted credentials, and execution statistics (record counts, timestamps, success/failure). Consent records and an audit log sit alongside this for CDR compliance.
What's absent is the point. There is no transactions table, no balances table, no holdings table, no trades table. They don't exist because the architecture has no reason for them to exist. The account metadata we do hold is limited, masked where appropriate, and subject to the same CDR deletion obligations as everything else — it goes when consent is withdrawn or the account is deleted.
Sync run records capture counts ("157 transactions processed, 42 new rows added") but never the transactions themselves. We can tell you that a sync ran successfully, but we cannot tell you what it synced.
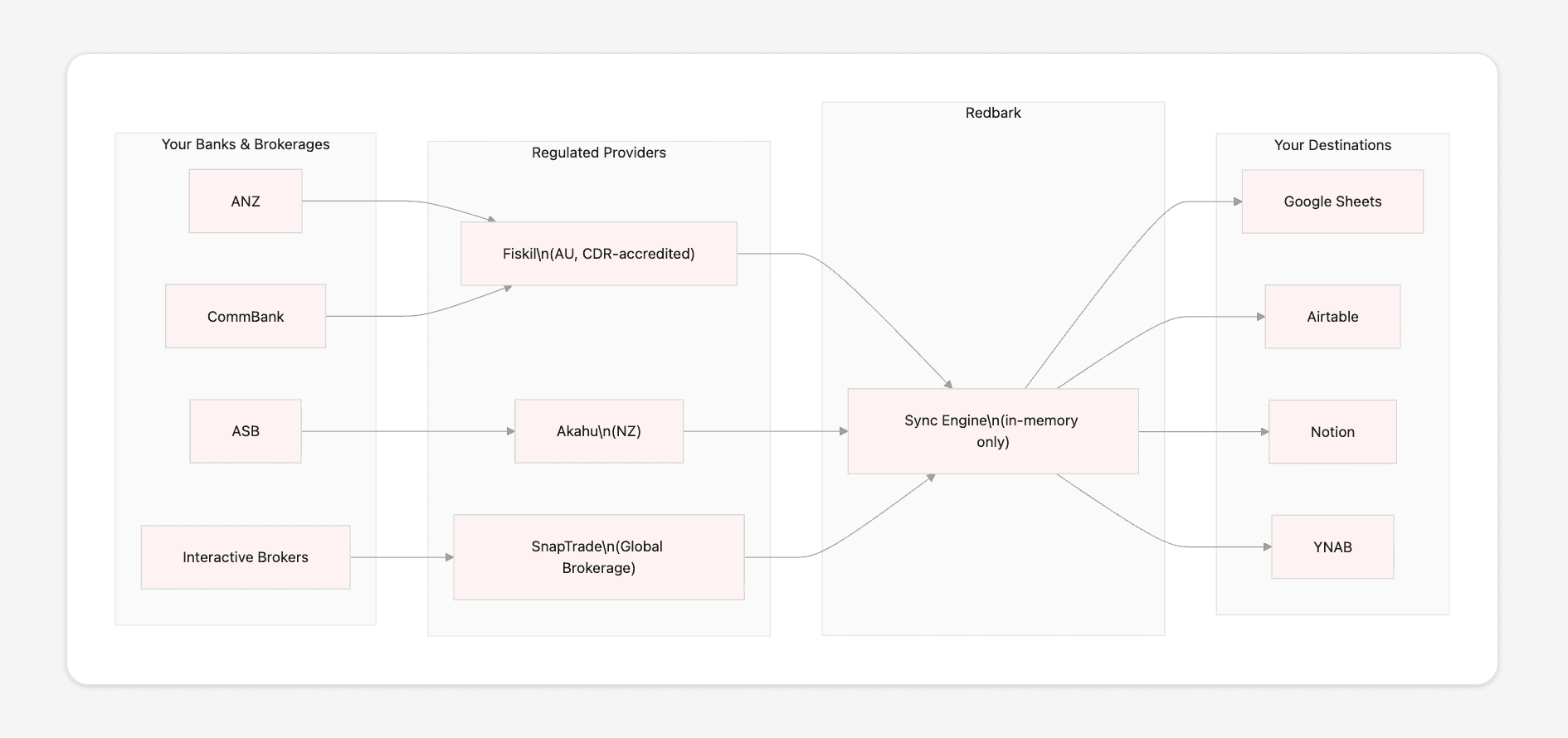
How data flows from bank to destination
The sync path has four participants: your bank, a regulated banking provider (Fiskil, Akahu, or SnapTrade), Redbark's sync engine, and your destination.
We don't connect to your bank directly. We work through regulated open banking providers: Fiskil for Australian banks (ACCC-accredited under the Consumer Data Right), Akahu for New Zealand banks, and SnapTrade for global brokerage accounts. These providers handle bank-level authentication and consent. We receive data from their APIs using short-lived, encrypted access tokens.
When your bank has new data, the provider sends us a webhook. Our sync engine loads the relevant configuration from the database, fetches transactions from the provider in pages of roughly 500 records, deduplicates against the IDs already present in your destination, and appends the new rows. The transaction data exists in application memory for the duration of this process, typically a few seconds, and is then released. Nothing is written to disk, to our database, or to our logs.
In practice, the sync engine is a set of background tasks running on Trigger.dev with concurrency limits per destination. Each task creates a sync run record (status: running), streams data through, updates the record (status: success, records added: N), and exits. The task has no persistent state between runs.
How credentials are handled
We store two categories of credentials, both encrypted at rest with AES-256-GCM.
Provider tokens let us fetch data from the banking API. For Fiskil, these are short-lived. They expire after 10 minutes and are refreshed automatically with a 2-minute buffer. For Akahu, tokens are long-lived but validated on each use. For SnapTrade, a user secret is generated at connection time and stored with a long expiry. In all cases, the encrypted token is decrypted in memory only when an API call is being made.
Destination tokens let us write to your Google Sheet or You Need a Budget plan. These are standard OAuth 2.0 tokens with refresh capability. They're encrypted before storage and refreshed proactively when they approach expiry, with a per-destination lock to prevent concurrent refresh races.
The plaintext form of any credential exists only in application memory, for the duration of the API call it's needed for. The encryption key is a 256-bit secret stored as an environment variable, never committed to source control, never logged.
CDR compliance and consent lifecycle
For Australian banking connections, the Consumer Data Right (CDR) framework governs how data is accessed and handled. Our architecture simplifies compliance because the hardest part of CDR data management, deletion of transaction data, is trivial when you never stored the transactions in the first place. The account metadata and consent records we do keep are small, structured, and cascade-deleted the moment consent is withdrawn.
Here's how our CDR implementation works. Every consent has an expiry date tracked in our database. A scheduled task runs daily to find expired consents, disable associated syncs, and notify affected users. Users can withdraw consent at any time through the dashboard, which immediately disables all syncs for that connection. A deletion queue then removes all consent-adjacent metadata: the connection record, account metadata, and encrypted tokens. An audit trail records every consent state transition for compliance purposes.
Consent withdrawal is a configuration change. We disable the sync pointers and delete the connection metadata. There is no cache of financial data to find and remove.
Webhook verification and request integrity
Every inbound webhook is cryptographically verified before we process it. Fiskil and SnapTrade webhooks are verified with HMAC-SHA256 using constant-time comparison to prevent timing attacks. Akahu webhooks use RSA-SHA256 with public keys fetched from their API. Stripe webhooks use Stripe's built-in signature verification.
Webhooks are the trigger for sync execution. A forged webhook could cause us to run a sync at an unexpected time. Signature verification ensures that only legitimate provider events trigger data movement.
The infrastructure behind it
Our infrastructure providers each maintain independent security certifications. Vercel (hosting) and PlanetScale (database) hold SOC 2 Type II. Clerk (authentication) holds SOC 2 Type II. Stripe (payments) holds PCI DSS Level 1 and SOC 2. Trigger.dev (background jobs) holds SOC 2 Type II. Fiskil operates as an ACCC-accredited CDR data recipient.
We chose these providers because they let us delegate security-sensitive responsibilities (user authentication, payment processing, data storage, bank connectivity) to services with appropriate compliance certification for each.
Where this is heading
The pass-through architecture is a constraint we chose deliberately. It means we can't build features that require a local copy of your data, like transaction search, spending analytics, or cross-account aggregation views. Those features would require storing financial data, and we've decided that isn't a tradeoff worth making.
What we can do is be a good pipe between your financial accounts and the tools you already use. If you have questions about our architecture or data handling, reach out at support@redbark.co.